1 Mydumper 介绍
Mydumper是一个针对MySQL和Drizzle的高性能多线程备份和恢复工具。
Mydumper主要特性:
- 轻量级C语言写的
- 多线程备份,备份后会生成多个备份文件
- 事务性和非事务性表一致的快照(适用于0.2.2以上版本)
- 快速的文件压缩
- 支持导出binlog
- 多线程恢复(适用于0.2.1以上版本)
- 以守护进程的工作方式,定时快照和连续二进制日志(适用于0.5.0以上版本)
- 开源 (GNU GPLv3)
1 | https://launchpad.net/mydumper |
2 mydumper 安装
mydumper使用c语言编写,使用glibc库
mydumper安装所依赖的软件包,glibc, zlib, pcre, pcre-devel, gcc, gcc-c++, cmake, make, mysql客户端库文件
- 安装依赖软件包,将mysql客户端库文件路径添加至/etc/ld.so.conf, 如/usr/local/mysql/lib
2. 解压软件包进入目录,cmake .
3. make && make install
安装步骤
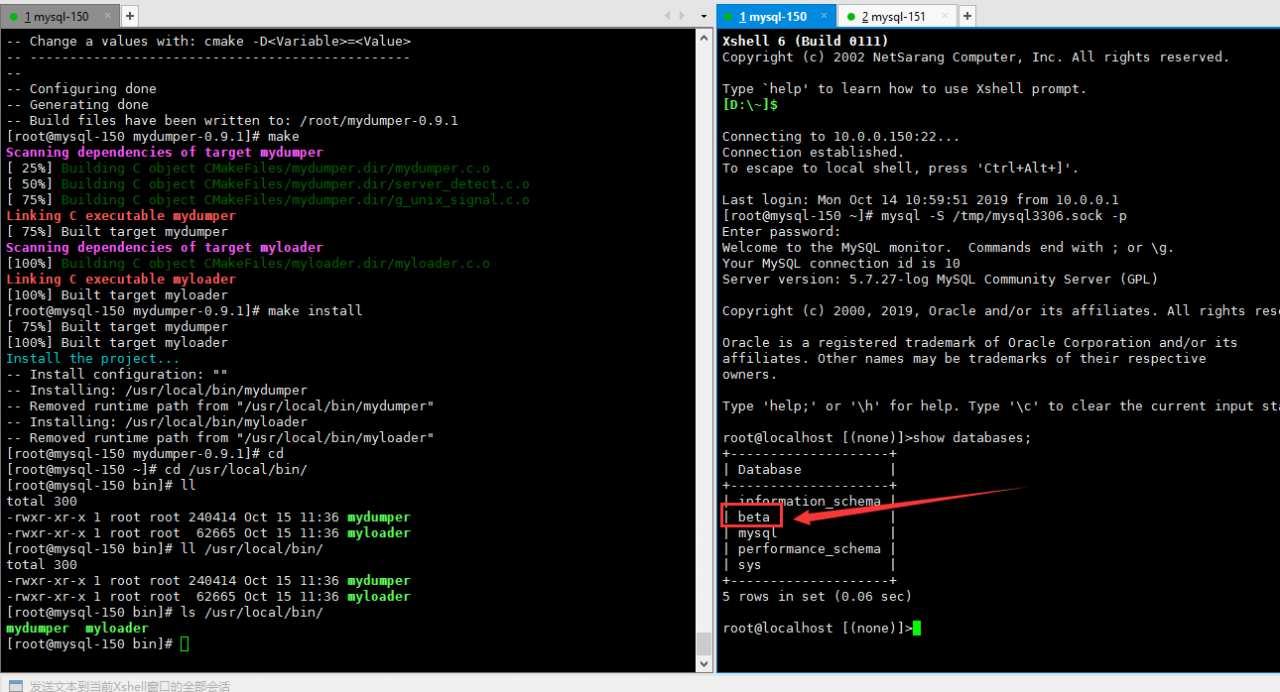
1 2 3 4 5 6 7 8 9 10 11 12 | [root@mysql-150 ~]# yum -y install glib2-devel mysql-devel zlib-devel pcre-devel zlib gcc-c++ gcc cmake[root@mysql-150 ~]# wget https://launchpad.net/mydumper/0.9/0.9.1/+download/mydumper-0.9.1.tar.gz[root@mysql-150 ~]# tar zxf mydumper-0.9.1.tar.gz[root@mysql-150 ~]# cd mydumper-0.9.1/[root@mysql-150 mydumper-0.9.1]# pwd/root/mydumper-0.9.1[root@mysql-150 mydumper-0.9.1]# cmake .[root@mysql-150 mydumper-0.9.1]# make[root@mysql-150 mydumper-0.9.1]# make install#安装完成后生成两个二进制文件mydumper和myloader位于/usr/local/bin目录下[root@mysql-150 bin]# ls /usr/local/bin/mydumper myloader |
2.1 mydumper 参数解释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | -B, --database 要备份的数据库,不指定则备份所有库-T, --tables-list 需要备份的表,名字用逗号隔开-o, --outputdir 备份文件输出的目录-s, --statement-size 生成的insert语句的字节数,默认1000000-r, --rows 将表按行分块时,指定的块行数,指定这个选项会关闭 --chunk-filesize-F, --chunk-filesize 将表按大小分块时,指定的块大小,单位是 MB-c, --compress 压缩输出文件-e, --build-empty-files 如果表数据是空,还是产生一个空文件(默认无数据则只有表结构文件)-x, --regex 是同正则表达式匹配 'db.table'-i, --ignore-engines 忽略的存储引擎,用都厚分割-m, --no-schemas 不备份表结构-k, --no-locks 不使用临时共享只读锁,使用这个选项会造成数据不一致--less-locking 减少对InnoDB表的锁施加时间(这种模式的机制下文详解)-l, --long-query-guard 设定阻塞备份的长查询超时时间,单位是秒,默认是60秒(超时后默认mydumper将会退出)--kill-long-queries 杀掉长查询 (不退出)-b, --binlogs 导出binlog-D, --daemon 启用守护进程模式,守护进程模式以某个间隔不间断对数据库进行备份-I, --snapshot-interval dump快照间隔时间,默认60s,需要在daemon模式下-L, --logfile 使用的日志文件名(mydumper所产生的日志), 默认使用标准输出--tz-utc 跨时区是使用的选项,不解释了--skip-tz-utc 同上--use-savepoints 使用savepoints来减少采集metadata所造成的锁时间,需要 SUPER 权限--success-on-1146 Not increment error count and Warning instead of Critical in case of table doesn't exist-h, --host 连接的主机名-u, --user 备份所使用的用户-p, --password 密码-P, --port 端口-S, --socket 使用socket通信时的socket文件-t, --threads 开启的备份线程数,默认是4-C, --compress-protocol 压缩与mysql通信的数据-V, --version 显示版本号-v, --verbose 输出信息模式, 0 = silent, 1 = errors, 2 = warnings, 3 = info, 默认为 2 |
2.2 myloader 参数解释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | -d, --directory 备份文件的文件夹-q, --queries-per-transaction 每次事物执行的查询数量,默认是1000-o, --overwrite-tables 如果要恢复的表存在,则先drop掉该表,使用该参数,需要备份时候要备份表结构-B, --database 需要还原的数据库-e, --enable-binlog 启用还原数据的二进制日志-h, --host 主机-u, --user 还原的用户-p, --password 密码-P, --port 端口-S, --socket socket文件-t, --threads 还原所使用的线程数,默认是4-C, --compress-protocol 压缩协议-V, --version 显示版本-v, --verbose 输出模式, 0 = silent, 1 = errors, 2 = warnings, 3 = info, 默认为2 |
使用案例:
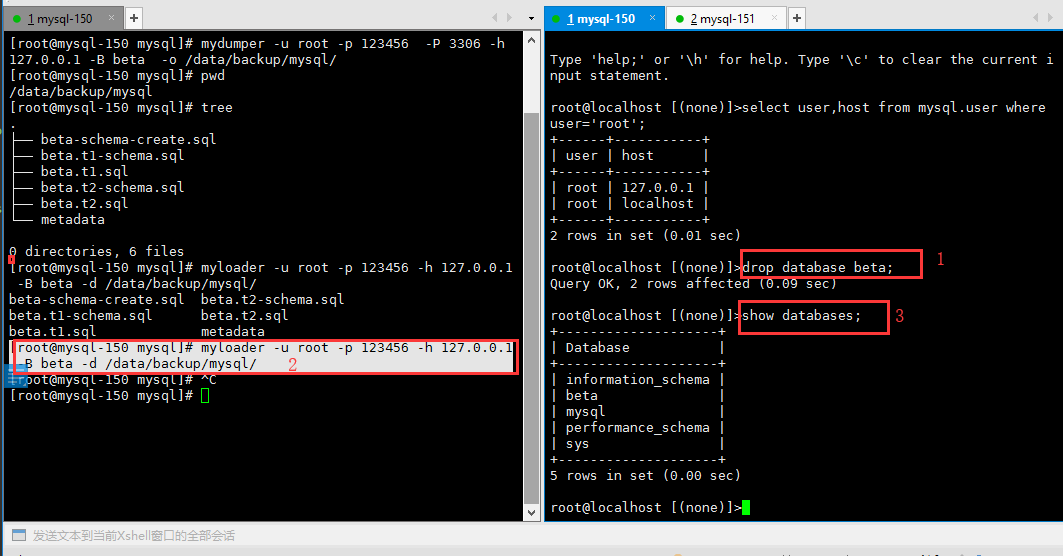
备份 beta 库 到 /data/backup/mysql 文件夹中
1 2 3 4 5 6 7 8 9 10 11 | [root@mysql-150 mysql]# mydumper -u root -p 123456 -P 3306 -h 127.0.0.1 -B beta -o /data/backup/mysql/[root@mysql-150 mysql]# pwd/data/backup/mysql[root@mysql-150 mysql]# tree.├── beta-schema-create.sql├── beta.t1-schema.sql├── beta.t1.sql├── beta.t2-schema.sql├── beta.t2.sql└── metadata |
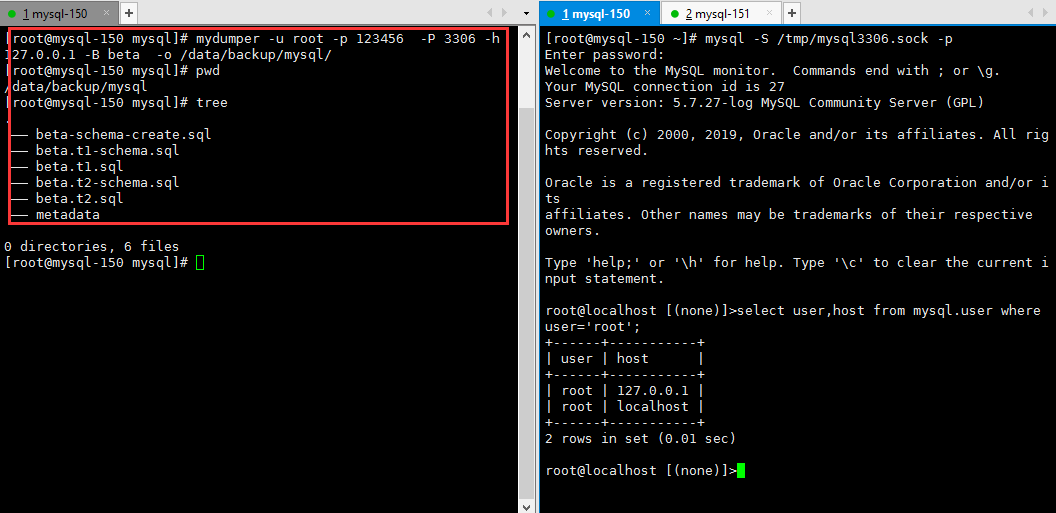
从上面可以可以看出
备份所生成的文件
目录中包含一个metadata文件
- 记录了备份数据库在备份时间点的二进制日志文件名,日志的写入位置,
- 如果是在从库进行备份,还会记录备份时同步至主库的二进制日志文件及写入位置
每个表有两个备份文件: - database.table-schema.sql 表结构文件
- database.table.sql 表数据文件
恢复 beta 库
1 2 3 4 5 6 | # 删除 beta 库root@localhost [(none)]>drop database beta;# myloader 恢复[root@mysql-150 mysql]# myloader -u root -p 123456 -h 127.0.0.1 -B beta -d /data/backup/mysql/# 验证root@localhost [(none)]>show databases; |
3 mydumper 备份原理
3.1 备份过程信息
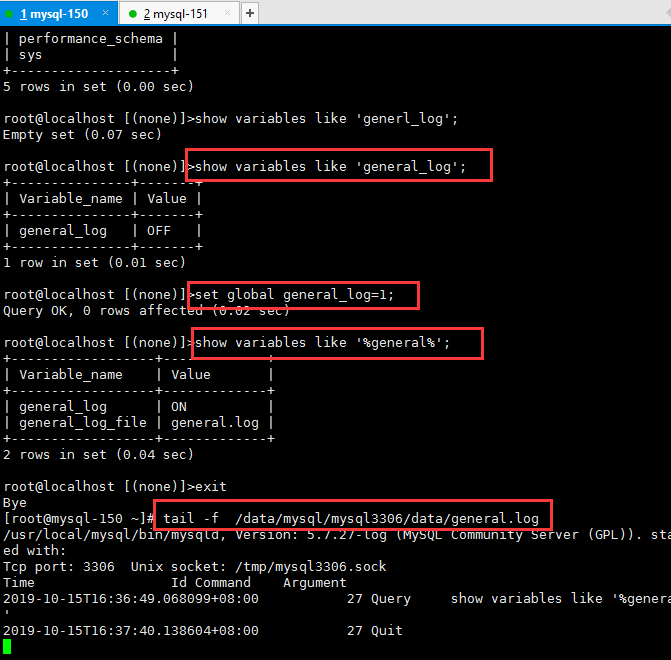
1. 先把general_log 打开
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | root@localhost [(none)]>show variables like 'general_log';+---------------+-------+| Variable_name | Value |+---------------+-------+| general_log | OFF |+---------------+-------+1 row in set (0.01 sec)root@localhost [(none)]>set global general_log=1;Query OK, 0 rows affected (0.02 sec)root@localhost [(none)]>show variables like '%general%';+------------------+-------------+| Variable_name | Value |+------------------+-------------+| general_log | ON || general_log_file | general.log |+------------------+-------------+[root@mysql-150 ~]# tail -f /data/mysql/mysql3306/data/general.log |
2. 删除原来备份数据,进行重新备份
1 2 3 4 5 6 7 8 | # 删除备份数据[root@mysql-150 mysql]# cd /data/backup/mysql/[root@mysql-150 mysql]# pwd/data/backup/mysql[root@mysql-150 mysql]# rm -rf *# mydumper备份[root@mysql-150 mysql]# mydumper -u root -p 123456 -P 3306 -h 127.0.0.1 -B beta -o /data/backup/mysql/ |
主要是这些步骤
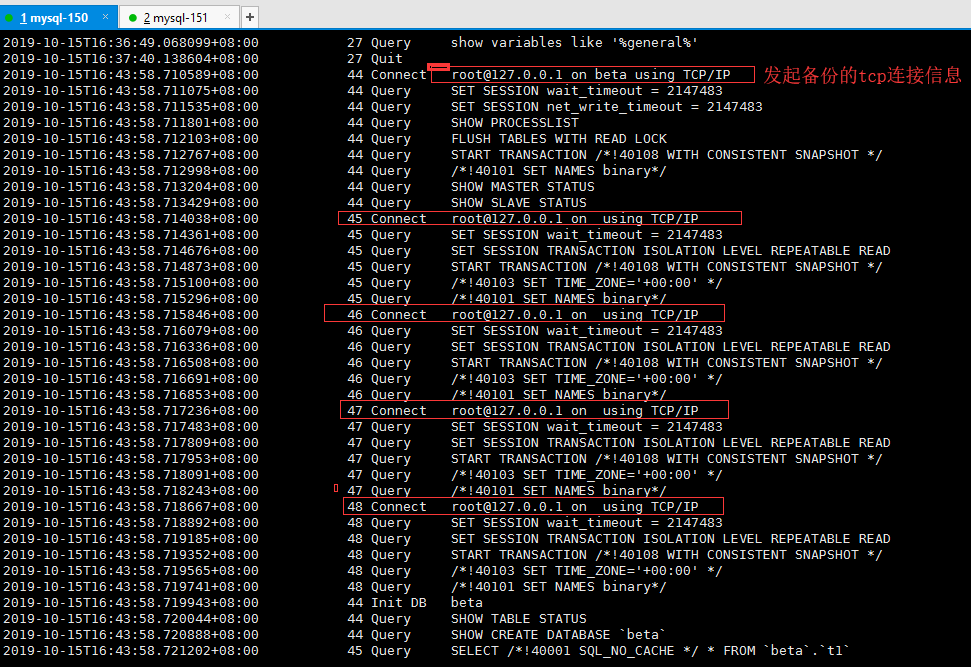

UNLOCK TABLES后截图没截图玩,最后有5个quit 信息
上面两个截图是完整的备份步骤
3. 单个库备份过程(这个库是的引擎是 innodb)
这里我总结一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | 1. 第一个发起备份的tcp信息FLUSH TABLES WITH READ LOCK # 加全局锁,防止写入START TRANSACTION /*!40108 WITH CONSISTENT SNAPSHOT */ # 开启事务/*!40101 SET NAMES binary*/ # 获取当前数据库的状态信息,就是数据库当前正在使用的二进制日志及当前执行二进制日志位置,执行了哪些GTID SHOW MASTER STATUSSHOW SLAVE STATUS2. 剩下的4个tcp 信息内容基本是同时工作的(也就是多线程),内容都是SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ #把当前会话事务隔离级别改为可重复读START TRANSACTION /*!40108 WITH CONSISTENT SNAPSHOT */ # 开启事务3. 获取相应的库信息,表信息,数据信息Init DB betaSHOW TABLE STATUSSHOW CREATE DATABASE `beta`SELECT /*!40001 SQL_NO_CACHE */ * FROM `beta`.`t1`SELECT /*!40001 SQL_NO_CACHE */ * FROM `beta`.`t2`SHOW CREATE TABLE `beta`.`t1`SHOW CREATE TABLE `beta`.`t2`4. 解锁 UNLOCK TABLES /* FTWRL */5. 最后备份结束,退出事务 |
注:由于我的库很小,所以一下就结束了。
3.2 备份原理
1、主线程 FLUSH TABLES WITH READ LOCK, 施加全局只读锁,保证数据的一致性
2、读取当前时间点的二进制日志文件名和日志写入的位置并记录在metadata文件中,以供即使点恢复使用
3、N个(线程数可以指定,默认是4)dump线程把事务隔离级别改为可重复读 并开启读一致的事物
4、dump non-InnoDB tables, 首先导出非事物引擎的表
5、主线程 UNLOCK TABLES 非事物引擎备份完后,释放全局只读锁
6、dump InnoDB tables, 基于事物导出InnoDB表
7、事物结束