网络文学随互联网的崛起而崛起,在时间日益碎片化的今天,网络文学以其方便快捷的特点适应了人们的娱乐性需求,因而也快速成长一个巨大的市场。娱乐是人们的根本性需求,文化是这个过程中的附属品。要想知道人们关心的是什么?什么又在兴起,哪些题材又在逐渐没落,我们需要从整体去分析。
因此这个爬虫也就应运而生,我们选取了目前国内最大的小说平台——起点网作为数据来源。本爬虫主要是为了爬取起点小说的基本信息(题目、作者、简介等),在写爬虫的过程中,我也碰到了一些有趣的反爬机制,这些小障碍我也会在本文中一并记录下来,希望能够给后来者一些帮助。
架构 \ 包
- 本爬虫主要是用Scarpy架构
- lxml(使用XPath需要的包)
数据存储
主要采用MongoDB数据库,MongoDB数据库在处理这种快速读写的数据有着非常高的效率,该部分主要通过修改pipelines来实现:
import pymongo
class MongoPipeline(object):
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_db=crawler.settings.get('MONGO_DB'),
mongo_uri=crawler.settings.get('MONGO_URI')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
self.db[item.collection].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
起点网的反爬机制
无论怎么看,起点网的反爬机制都是很业余的,我本来以为需要构建一个IP池,或者说限制住访问速度才能爬的下来;但这些都没有用到,基本上只要写完基本的Scrapy我们就能得到所需要的数据。
但在爬取网站数据的时候,我遇到了相当多次访问连接失效的问题,不管是使用爬虫访问还是直接用浏览器访问,这种情况都不少,对此我认为起点网的后台代码也许写的真的很烂,但就是这么烂的代码支撑起了中国网络文学界的半壁江山。果然在业务确定、行业壁垒已经建立的情况下,只要代码能跑得动,就不需要大修。
那么起点网主要使用了哪些反爬机制呢?
1. 数字乱码
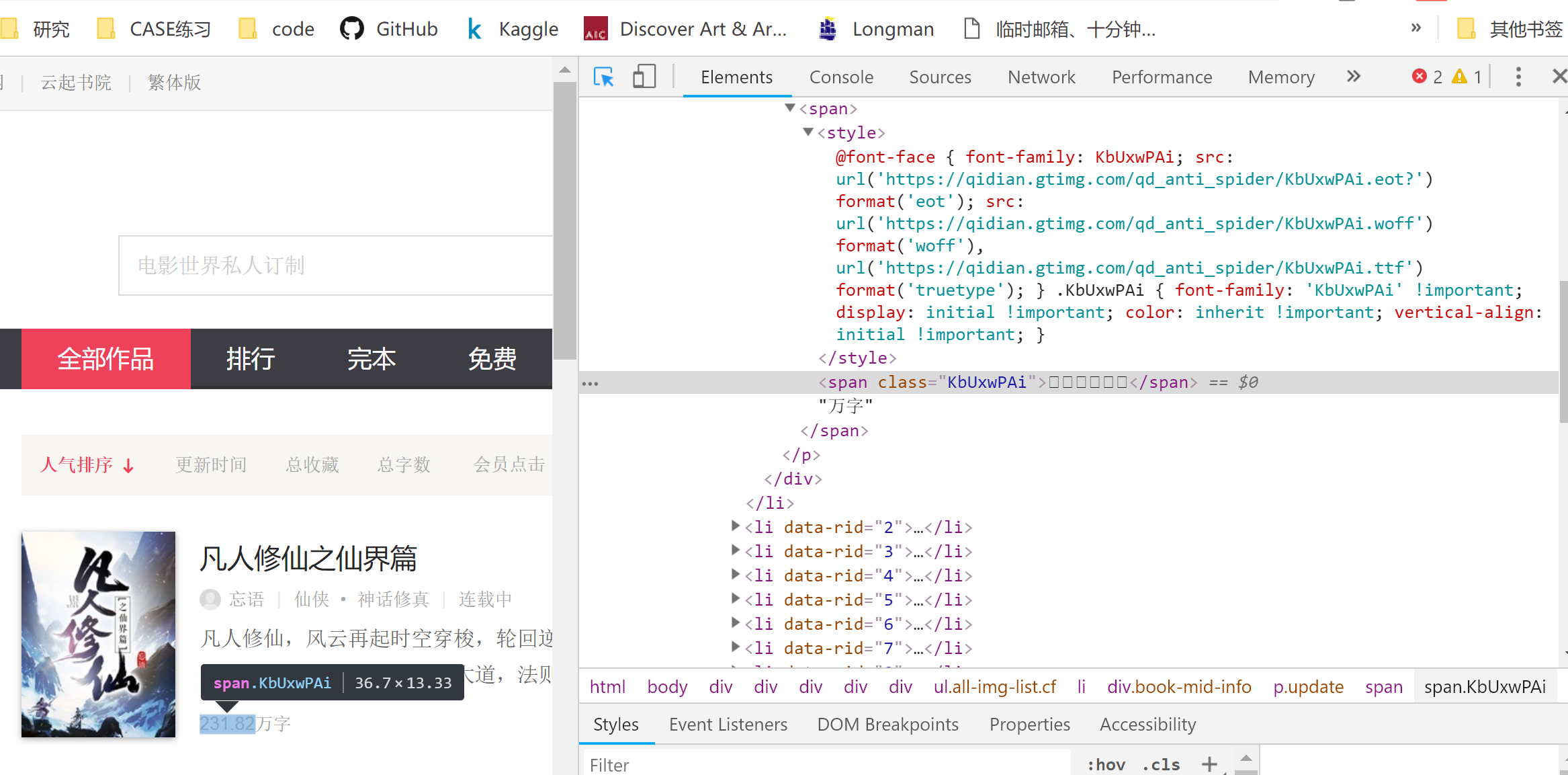
我们可以通过F12键打开控制台,在Elements中查看到这一反爬机制;此处我已经截图,我们可以看到:
原本在浏览器中清晰可见的数字,在element(HTML)代码中变成了乱码,这是起点给予的第一个反爬机制。

<center>源码</center>
原本我以为是由于编码的问题导致的控制台查看出现了乱码,在后台我看到数字的编码为𘡁等,开始我尝试去搜索这是什么编码,走了很多弯路后发现这其实是一个映射。源码对应的字符部分其实表示的是某种字体的英文显示,如在截图中,该字体为KbUxwPAi;了解到这些,我们要做的就是构建起这个映射,然后解码出对应的数字,该部分的思路如下:
- 获取页面的字体文件链接(通过正则表达式)
- 通过fontTool木块获取当前字体映射关系
- 建立起英文映射
- 通过pyquery进行数据提取
该部分代码如下(spider中的qidian.py)
def get_font(self,Pageurl):
response = requests.get(Pageurl).text
doc = pq(response)
# 获取当前字体文件名称
fonturl = doc('p.update > span > style').text()
url = re.search('woff.*?url.*?\'(.+?)\'.*?truetype',fonturl).group(1)
response = requests.get(url)
font = TTFont(BytesIO(response.content))
cmap = font.getBestCmap()
font.close()
return cmap
def get_encode(self,cmap,values):
WORD_MAP = {'zero': '0', 'one': '1',
'two': '2', 'three': '3',
'four': '4', 'five': '5',
'six': '6','seven': '7',
'eight': '8', 'nine': '9',
'period': '.'}
word_count = ''
for value in values.split(';'):
value = value[2:]
key = cmap[int(value)]
word_count += WORD_MAP[key]
return word_count
2. 链接转换
因为起点小说网全部分类下面虽然有显示五万多页的作品,但一般爬虫抓到5000多页就会发现没有办法获取到有效数据了,也就是说全部分类下的5000页之后的数据基本都是摆设,对此我换了个思路想先抓取到一二级分类的所有内容之后在通过更换url中的page=?来更多的抓取数据。
但这也就碰到了第二条反爬机制
我们直接单击玄幻分类可以跳转到玄幻分类的第一页,此时链接是这个样子的:
https://www.qidian.com/all?page=1&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0
而如果我们打开第二页会发现链接变成如下所示
https://www.qidian.com/all?chanId=21&orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page=2
对比可以发现,page更换了位置,其实只要细心点就能绕过这个坑;解决这个小问题之后,之后的爬取就畅通无阻了。
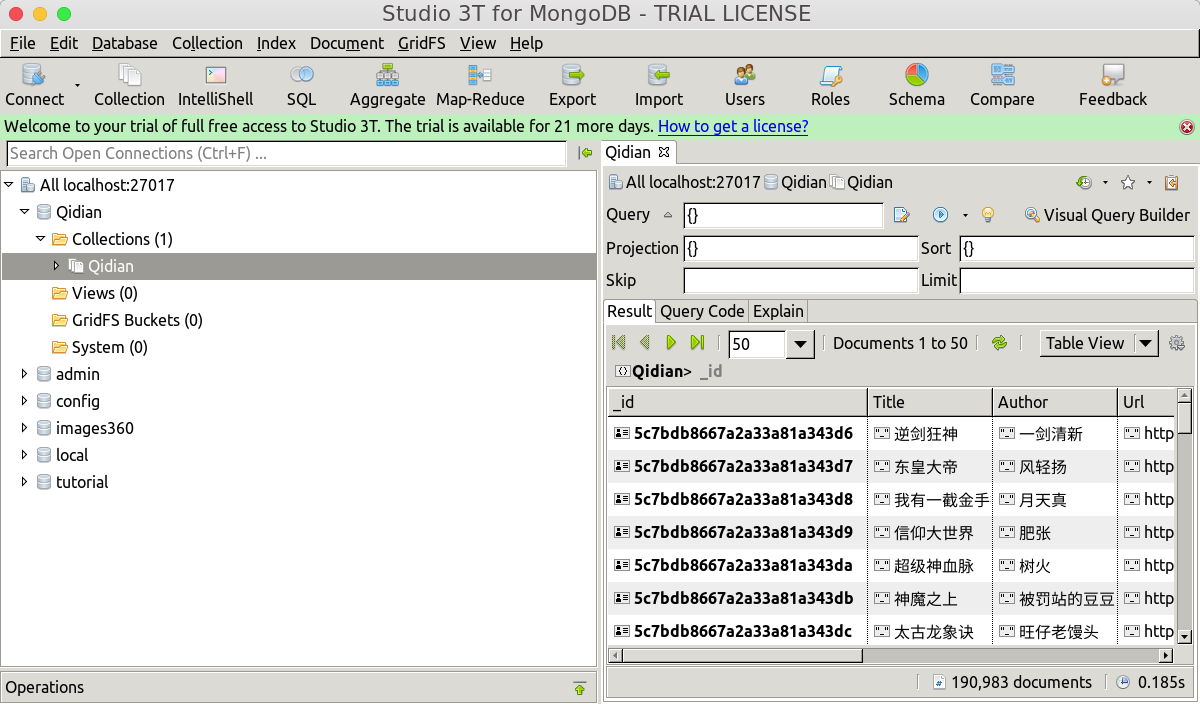
但因为网络链接的不稳定和代码不够健壮的问题,其实离爬取起点的全网数据还是有一定距离的,起点全网有112万本小说,我们最终爬取的小说数目为19万左右,除去其有一些小说一直没有展示出来,代码还是不够健壮。
其他
需要着重强调的部分我已经说的差不多了,剩下的诸如定义Items等都是Scrapy的基础,在这里就不过多的赘述,在写完代码之后我们可以直接运行
scrapy crawl qidian
来抓取运行爬虫,之后你会看到数据如激流一般在屏幕上流淌
以上。
github源码地址:起点小说网全站爬虫
作者:关芦东Carlous
链接:https://www.jianshu.com/p/1fa78bb0ece4
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。