方法
做过好几个关于网站全站的项目,这里总结一下。
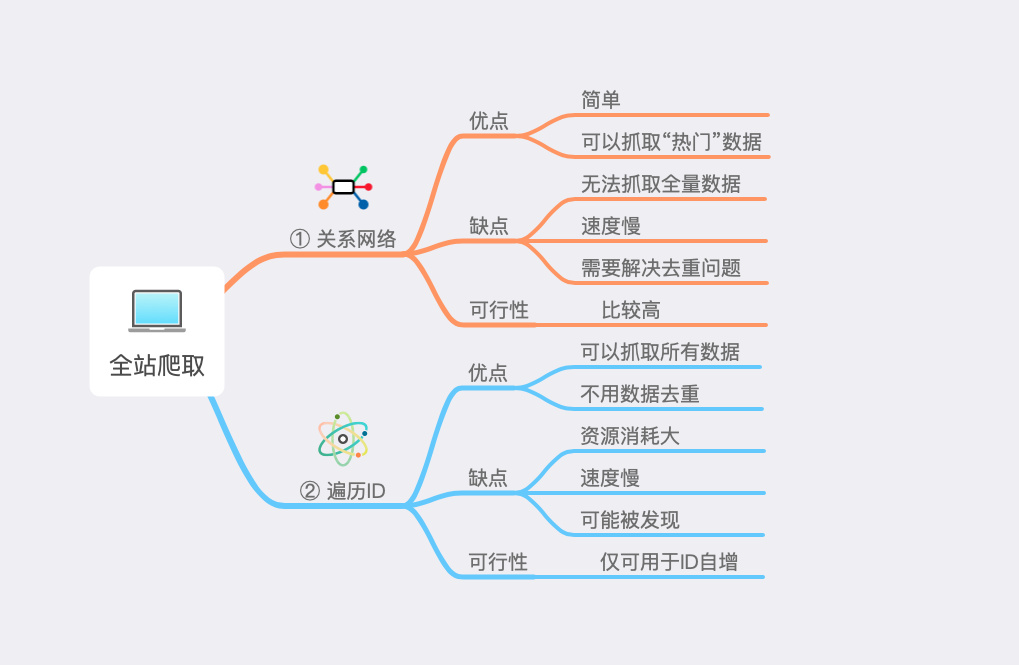
先把上面那张图写下来,全站爬取的两种方法:
关系网络:
优点:简单;可以抓取“热门”数据
缺点:无法抓取全量数据;速度慢;需要解决去重问题
可行性:比较高
遍历ID
优点:可以抓取所有数据;不用数据去重
缺点:资源消耗大;速度慢;可能被发现
可行性:仅可用于ID自增
关于关系网络
其实这个很好理解。比如说知乎,一个大V有100W粉丝,从这个大V出发,抓取粉丝的粉丝,一直循环下去。(可能是个死循环)
这个方法就比较简单,Scrapy中就是继承CrawlSpider,再编写匹配规则就好。
Example
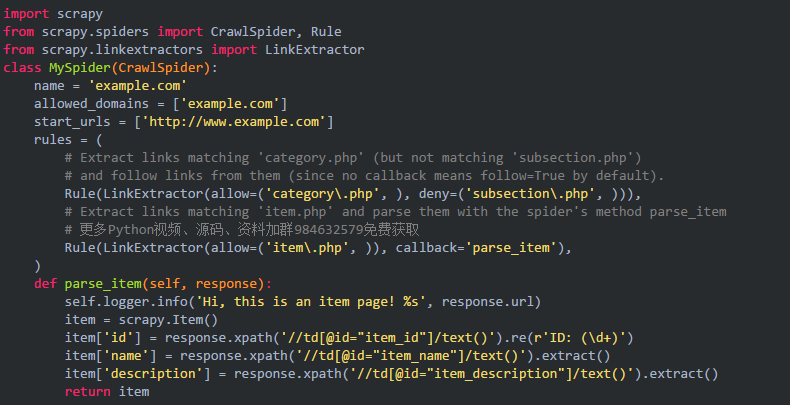
这种方法一般是搜索引擎会做的。而且抓取的内容基本是最多人看到的,所以月排在前面,和SEO有关。
但是这种方法的缺点也是很明显的,最明显的就是没法抓全数据,像那种冷门的数据就没法抓取到,速度也是比较慢的,必须保存去重队列,以防止重复抓取页面。(了解下布隆过滤器)
如果对数据完整性要求没那么高可以考虑这种方法。
遍历ID
找各种方法就比较无脑了,啥也不用想,从0开始遍历跑吧。
毫无疑问,这种方法可以抓取网站所有的数据,因为在开始抓取前就已经完成的去重,所以这方面就不用管了。
但是缺点也很明显,因为是遍历ID,所以需要很多服务器资源和代理资源,有可能某个ID已经下架或失效。所以整个工程请求量会非常大。而且可能被别人发现,一般人都去看那些热门帖子,结果你把那么重来没人看的翻了一遍,别人也会发现数据异常的(也会存在假数据的情况?)。
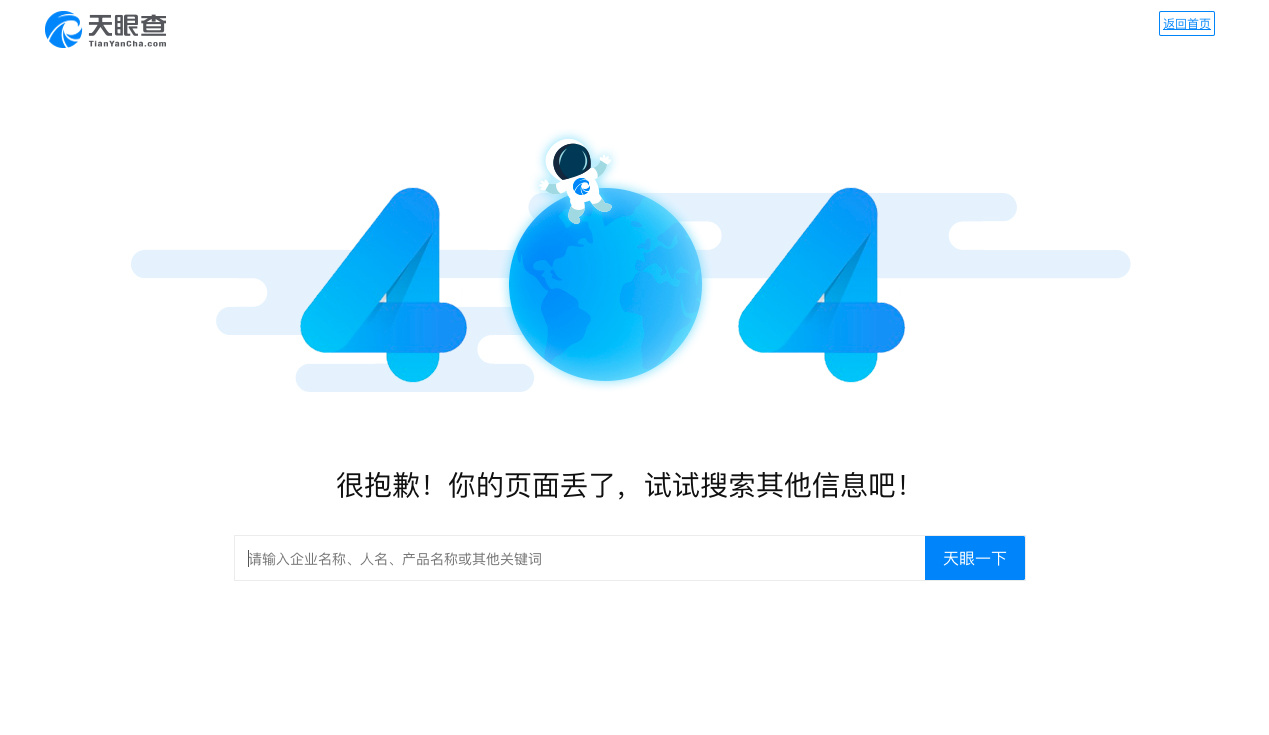
而且这种方法之适用于ID自增的,大多数是数字ID递增,比如说天眼查的:

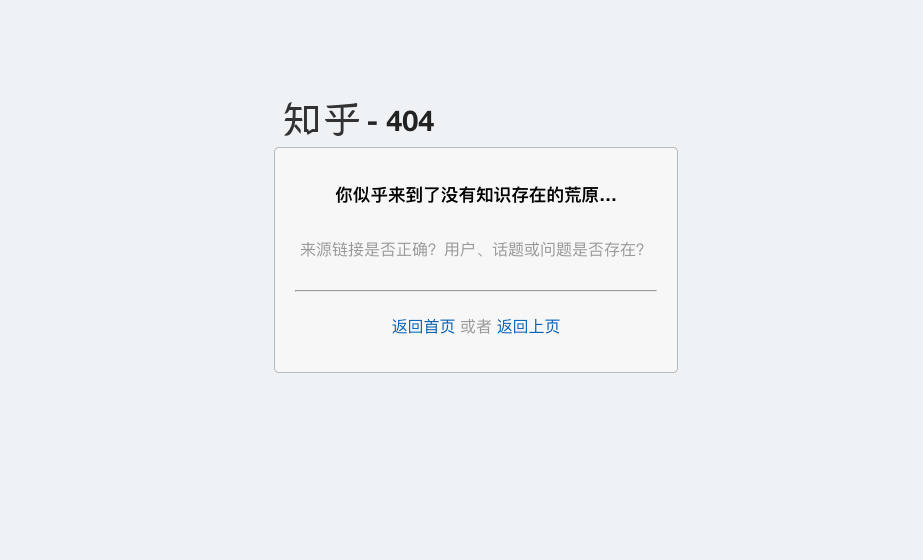
知乎也是:

应该是和数字有关系,可以先采样进行抓取,研究数据分布情况。
当提供不正确ID时,也会返回数据不存在的情况
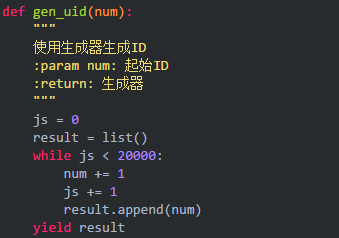
在这里提供一个生成ID的方法
最后再看看这张图。两种方法都有优缺点,根据实际需求选取,如果你还知道别的抓取方法,欢迎指出。
作者:我爱学python
链接:https://www.jianshu.com/p/c799fc116638
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。