最近在分析数据时,遇到1000万条csv数据,于是便想着将其导入MySQL进行分析,由于本人比较笨,折腾了一晚上还没搞定,总是遇到各种各样的错误,终于在今天成功导入了这1000万条数据,在此跟大家分享一下:
一、工具
- MySQL-8.0.15
- notepad++.7.4.2
二、过程.
- 首先先建好相应的数据库和表
具体过程大家可以自己根据自己数据实际情况建库和表,重点各字段名只能全部为文本类型(char,varchar等)
注:这里有个细节要跟大家说一下,数据库和表的名字不能有“–”等符号,但下划线可以,不然后面会出错(后面有图) - 之后就是数据的处理
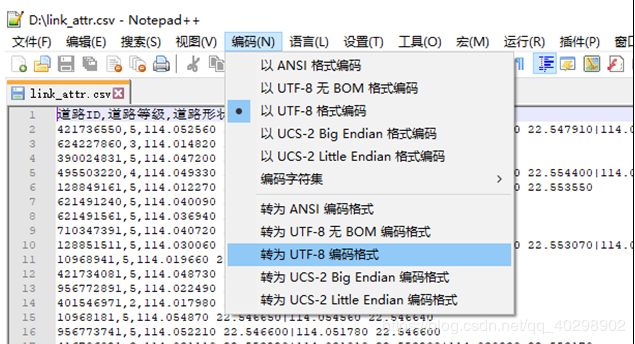
由于数据量过大,用exce只能打开部分数据,所以这里要用 notpad ++打开,然后将数据转化为utf-8编码

打开MySQL目录下的my.ini文件,在里面添加,secure_file_priv=‘文件导入的数据源’;以后要导入的数据源都要放在这个目录下才可以导入,如:secure_file_priv=’D:/’
3. 数据导入
切换到相应的数据库下面:use 数据库名;
数据开始导入:
load data infile 'D:/traffic_shenzhen.csv'into table traffic_shenzhen fields terminated by ',' optionally enclosed by '"' escaped by '"' lines terminated by '\n';
解读:
D:/traffic_shenzhen.csv:数据的存放路径(注意上面所说的路径要与my.ini文件里面添加的位置一致)
traffic_shenzhen:数据库下要存放的表
fields terminated by ‘,’:表示每个字段用逗号分开
optionally enclosed by ‘"’ escaped by ‘"’:内容包含在双引号内
lines terminated by ‘\n’:每行的换行(注意:window系统用‘\r\n’,linux系统用‘\n’)
这里可以看出插入的数据有11077919条数据,用时3分钟45秒
注:一般这样写是不会错的,除非是在一些细节上没处理好,这些细节在上面都有用“()”或“注”指出,下面也会再进行一些错误分析。
三、错误分析
一般只要按照上面的步骤来是不会错的,主要是细节方面的问题,细心点就好,要是实在遇到很多错误也不要心浮气躁,一般的错误网上可以找得到的,毕竟人非圣贤,有错误也正常,主要心态要好,毕竟这是一个学习的过程,有错误才有收获,你说对吗!
- .错误1:

解:这里就像我说的,在数据库和表的命名时不能有“-”符号,不然就会有这样的错误提示,所以只要把数据库和表的名字改一下(不要包含“-”符号)就行了。 - notepad++.7.4.2

解:这里命令的写法跟错误1的写法作用是一样的,这里是编码的问题,我在上面的数据处理那里说过,要先用notpad++打开,转为utf-8编码就可以解决了。 - 错误3:

解:这里就像字面意思一样,没有选择是哪个数据库,所以只要在执行这些命令之前,先执行“use 数据库名;”就可以了。 - 错误4:

解:这里的错误是数据库下的表结构导致的,意思就是“道路形状坐标”这一列,你之前给它创建时范围太小了,csv文件里面的对应的数据太大,数据库下的表存不下,所以,只要把数据库下的表中的“道路形状坐标”这一列的范围改大一点就可以了。 - 错误5:

解:这里只要打开MySQL目录下的my.ini文件,在里面添加,secure_file_priv=‘文件导入的数据源’;以后要导入的数据源都要放在这个目录下才可以导入,如:secure_file_priv=‘D:/’ - 错误6:

解:这里是字段的类型不对,可以字段类型改一下就好,比如:全部改为varchar类型等。
以上就是本次千万级别数据导入的全部内容,希望对大家有用,如有说得不对得地方希望大佬指出,本文纯属原创,如有侵权,可联系本人博主删除。
https://blog.csdn.net/qq_40298902/article/details/89336086