最近有个项目需要采集一些网站网页,以前都是用php来做,但现在十分流行用python做采集,研究了一些做一下记录。
采集数据的根本是要获取一个网页的内容,再根据内容筛选出需要的数据,
python的好处是速度快,支持多线程,高并发,可以用来大量采集数据,缺点就是和php相比,python的轮子和代码库貌似没有php全,而且python的安装稍微麻烦了点,折腾了好久。
python3的安装见连接:
https://www.cnblogs.com/mengzhilva/p/11059329.html
工具编辑器:
PyCharm :一款很好用的python专用编辑器,可以编译和运行,支持windows
python采集用到的库:
requests:用来获取网页的内容,支持https,用户登录信息等,很强大
lxml:用来解析采集的html内容,十分好用,比较灵活,但很多用法不好找,api文档不好找。
pymysql:连接操作mysql,这个就不用说了,将采集到的信息存到数据库。
基本上这三个就可以支持采集网页
安装代码:
用pip安装调用代码:
pip install pymysql
pip install requests
pip install lxml
采集数据:
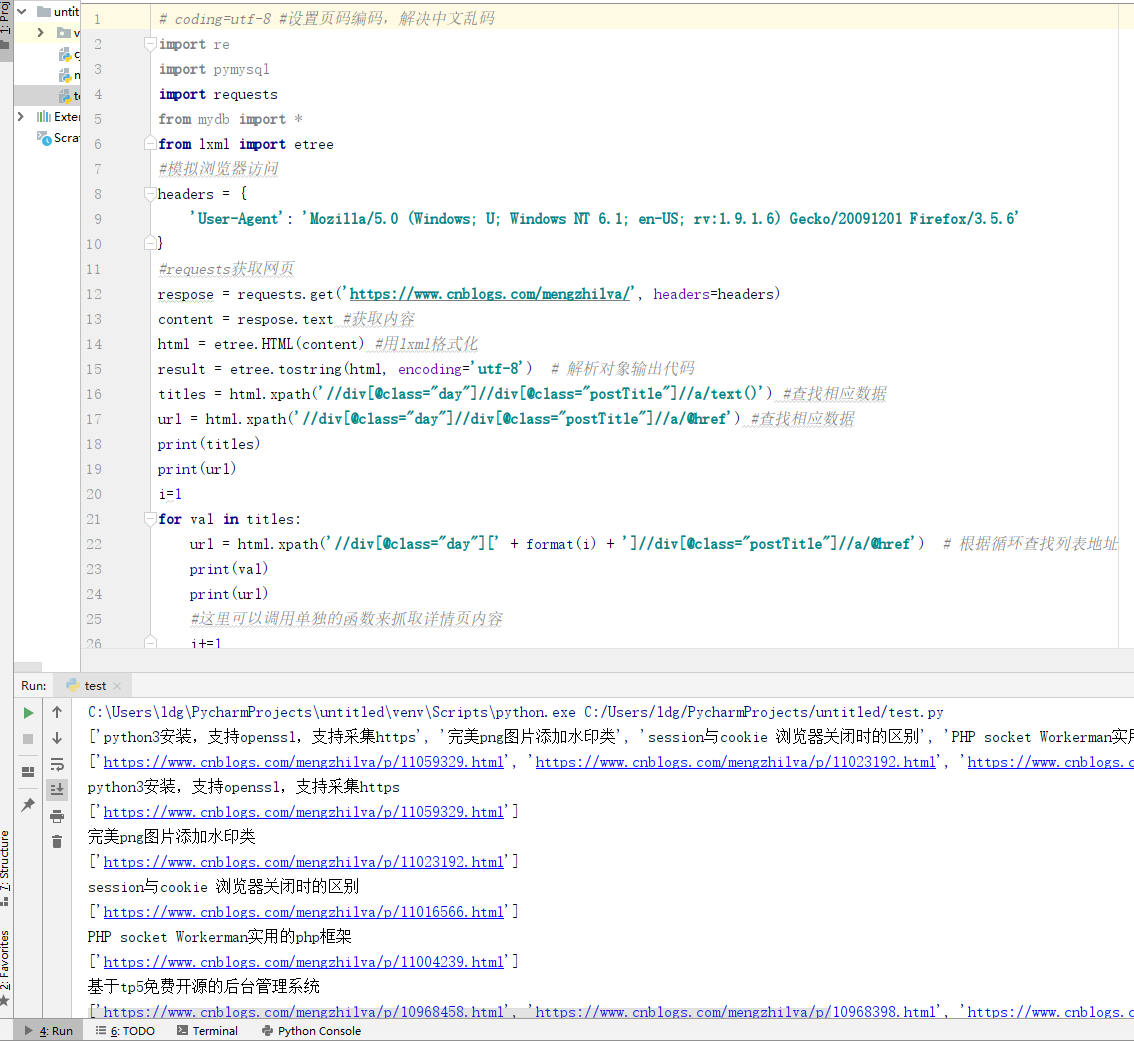
采集的代码和打印的结果:
# coding=utf-8 #设置页码编码,解决中文乱码
import re
import pymysql
import requests
from mydb import *
from lxml import etree
#模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
#requests获取网页
respose = requests.get('https://www.cnblogs.com/mengzhilva/', headers=headers)
content = respose.text #获取内容
html = etree.HTML(content) #用lxml格式化
result = etree.tostring(html, encoding='utf-8') # 解析对象输出代码
titles = html.xpath('//div[@class="day"]//div[@class="postTitle"]//a/text()') #查找相应数据
url = html.xpath('//div[@class="day"]//div[@class="postTitle"]//a/@href') #查找相应数据
print(titles)
print(url)
i=1
for val in titles:
url = html.xpath('//div[@class="day"][' + format(i) + ']//div[@class="postTitle"]//a/@href') # 根据循环查找列表地址
print(val)
print(url)
#这里可以调用单独的函数来抓取详情页内容
i+=1
原文出处:https://www.cnblogs.com/mengzhilva/p/11059768.html