一、字符集
字符集:就是用来定义字符在数据库中的编码的集合。
常见的字符集:utf8、Unicode、GBK、GB2312(支持中文)、ASCCI(不支持中文)
二、字符集排序规则
作者本人用的是utf8_general_ci
- 后缀ci (case insensitive)意味不区分大小写(大小写不敏感),后缀cs (case sensitive)区分大小写(大小写敏感)
- utf8_bin 规定每个字符串用二进制编码存储,区分大小写,可以直接存储二进制的内容
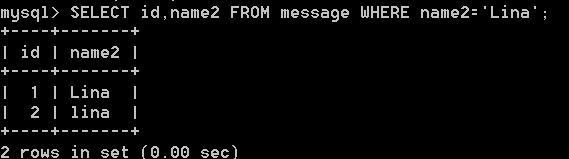
- 如ci情况下:select name,age from userinfo; 等价于SELECT NAME,AgE FROM userinfo; 大小写字符判断是一样的
- 而在cs情况下:假设字段名严格为name, age,表名:UserInfo。那么就必须:select name,age from UserInfo; 大小写字符判断有区分
- 而bin意思是二进制,所以小写u和大写U会被区别
例如你运行:
SELECT name FROM UserInfo WHERE name = ‘Lina’
那么在utf8_bin中你就找不到 name = ‘lina’ 的那一行, 在utf8_general_ci 下可以.
1. utf8_general_ci 不区分大小写,这个你在注册用户名和邮箱的时候就要使用。
2. utf8_general_cs 区分大小写,如果用户名和邮箱用这个 就会照成不良后果
3. utf8_bin:字符串每个字符串用二进制数据编译存储。 区分大小写,而且可以存二进制的内容
utf8_unicode_ci和utf8_general_ci对中、英文来说没有实质的差别。
utf8_general_ci校对速度快,但准确度稍差。
utf8_unicode_ci准确度高,但校对速度稍慢。
utf8_unicode_ci比较准确,utf8_general_ci速度比较快。通常情况下 utf8_general_ci的准确性就够我们用的了,在我看过很多程序源码后,发现它们大多数也用的是utf8_general_ci,所以新建数据 库时一般选用utf8_general_ci就可以了
总结:
排序规则,就是指字符比较时是否区分大小写,以及是按照字符编码进行比较还是直接用二进制数据比较。
人生还有意义。那一定是还在找存在的理由