学习了这么久PHP,基础知识总感觉不牢靠,尤其是数组,字符串函数的应用,全部手敲过次手,做出总结
都是基础,在回顾一下吧。
一。PHP基础语法
变量,常量
严格区分大小写,但内置结构或关键字无所谓(echo)
命名:不能以数字,空格,.来开头,但是可以有汉字,eg:$变量=”aa”;
可变变量:$a=’aa’;$$a=”bb”;则 $aa=”bb”;
引用赋值:$a=”aa”; $b=&$a; 则改变$a的值,$b也变化。不同:存储结构是分开的,即使unset($a),$b还在(区分C语言)
变量类型:int str array bool object float resource null
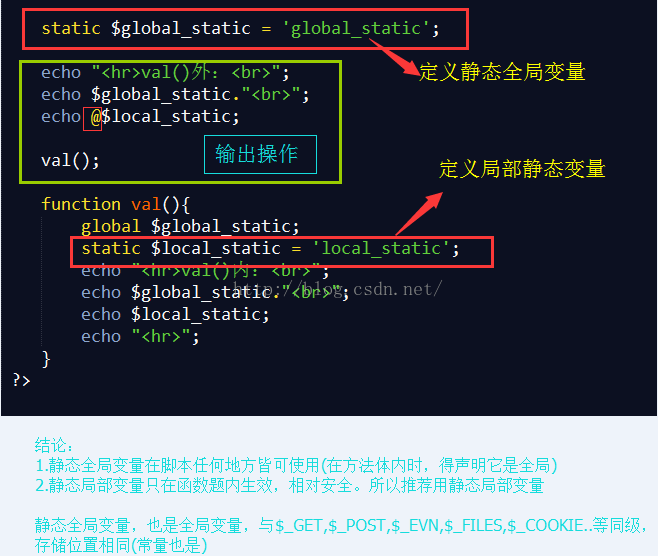
全局变量:全局变量本身就是静态存储方式,所有的全局变量都是静态变量
$_SESSION, $_COOKIE, $_POST, $_GET, $_REQUEST, $_FILES,$_EVN
静态变量:
static [详细见下图]
静态方法:静态方法不需要所在类被实例化就可以直接使用。Math::Max($a,$b);(未实例化Math类直接调用静态方法Max)
常量:
define(“NAME”,$value,[TRUE]);//如果第三个参数为true,则不区分大小写,默认是区分大小写的
预定义常量:
PHP_OS=”WINDOWS”; PHP_VERSION=”版本”;
E_ERROR=1,错误,导致脚本终止; E_WARNING=2,警告,脚本不终止 ;E_NOTICE=8,非关键性错误
魔术常量:【全是返回物理路径,即使被包含输出,输出的也是源头代码的信息,非当前包含文件的信息,和$_SERVER区分】
__FILE__ 当前文件名称
__CLASS__ 当前类名称
__FUNCTION__ 当前函数名称
__METHOD__ 当前方法名称
__LINE__ 当前行数名称


总结:
(全局)常量:(默认常量就是全局的)存储在(静态)数据段
变量
全局变量:存储在静态数据段
局部变量:存储在栈中
静态变量:(不管全局/局部)存储在静态数据段中
类型转换
1.setType($a);//获取变量的类型
2.$b=(int)$a;//把$a转换为整形
$b=intval($a);
3.is_int($b);//判断$b是否为整形,返回bool值
类型转换:(int),(bool),(float),(),(string),(),(array),(),(object);
intval(),floatval();strval()
判断类型:
is_bool/int/float/string/array/object/resource/null
is_numberic();’//判断是否为任何类型的数字或者数组字符串
is_callable();//判断是否为有效函数名称
运算符
算数运算符:+ – * / % ++ —
连接运算符: .
赋值运算符: =, +=,-=,*=,/=,%=,.=
比较运算符:>,<,==,===,!= <>,!==
逻辑运算符: and,&& ; or,|| ; not,! ; xor(逻辑异或,两边不同返回TRUE,相同返回FALSE)
位运算符 : & ;|;^(异或,不同返回1);~(非运算符,1.0取反);<<左移,右边空出的补0;>>右移左边空出的补0
其他运算符:
?: 三目运算符 举例:$a=$bool?$b:$c; //若$bool成立,$a=$b;否则$a=$c
@ 忽略错误
=>数组下标用
->调用对象值用
·· 反引号为执行运算符??
instanceof 类型运算符 class ClassOne{} $a=new ClassOne(); var_dump( $a instanceof ClassOne );//返回true
流程控制
1.if(){}else{}
2.while(){};
3.do{}while();$
4.for($a=1;$a<10;$a++){}
5.switch($a){
case 1:echo 1; break;
case 2:echo 2;break;
default: echo “this is defaut value”;
}
continue,break;exit 区别:
continue跳过当前循环,循环还在继续
break 跳出当前循环,循环终止
exit; 终止当前脚本,这行代码后边的代码不执行了就
函数
命名:遵循变量命名规则即可,函数不可一被重载、
作用:函数实现了结构化编程,提高了代码的可维护性
全局变量:整个脚本中皆可以使用
局部变量:只有在函数体内使用,执行完函数自动释放
|—> 分为静态存储类型和动态存储类型; static $a为静态变量,函数执行完后,不会被释放
函数内局部变量编程全局变量:1.global ; 2.$GLOBAL[”]使用全局数组
几种类型函数
1.引用参数的函数:function(&$a){}//函数内对形参$a的操作,会对实参也造成影响 eg:sort()
2.默认参数的函数:function($a=0){}//没有参数传入的话,默认$a=0
3.可变参数个数的函数:function($a,$b$c,…){}
//原理:通过fun_get_args()函数,接受所有参数并返回一个数组来使用,所以可以有多个参数 EG: echo(),array_merge()
4.回调函数:$fun=”one”; function one(){} 当调用$fun()的时候,就是再调用one()函数,call_user_func_array()
5.递归函数:function test(){ test()}//在函数中再次调用函数,但注意死循环的问题,要有执行结束跳出
二。PHP常用函数
常用函数:
echo()【语言结构】
print()//【语言结构】【有返回值】,若传输失败导致没有输出,它返回false
var_dump()
var_export()【有返回值,翻译一个合法的PHP代码】
printf()//类似与C语言的形式 printf(“my name is %s, age %d”, $name, $age);,打印出来
sprintf()//跟printf相似,但不打印,而是返回格式化后的文字,其他的与printf一样
数组函数:
1.排序类:【1.无返回值,传值引用,就直接对原数组进行了修改】
按V:sort,rsort,asort,arsort,
按K:ksort,krsort
按字母:natsort();//区分大小写的排序
natcasesort();//不区分大小写的排序,
当遇到字符完全一样,按照数字排 eg: FILE1,FILE2, 这两个字符相同,再按照数字1<2排,所以结果 FILE1,FILE2
回调:usort($arr,”strnatcmp”)//回调类的排序,把$arr数组里的每一个元素丢到strnatcmp()[非自然数排序]处理【返回新的排序数组】
规律:
没有”k”,排序按照【value】排序,排序有”a”的表示要保留KEY,有”r”的倒序排
有“k”,排序按照【KEY】排序,有”r”的倒序排
有”u”的,表示要丢到回调函数中处理的
2.键值操作类:【都有返回值,没有在原来参数上修改】
1.array_values($arr);//获取$arr中的值重排,去掉下标【返回值新索引数组】
2.array_keys($arr[,”str”,true])//获取$arr中所有字符是”str”的下标,形成索引数组,true表示区分大小写【返回新索引数组】
3.array_search(“is”,$arr[,true]) //返回值”is”在$arr中的key,找不到返回fales,true表示严格按照类型(8,”8″)【返回第一个匹配值】
4.in_array(“str”,$arr);//判断”str”在$arr中是否存在,【返回BOOL】
5.is_array($arr);//判断是否是数组【返回BOOL】
6.array_key_exists($key,$arr); //查询$arr中是否有$key,【返回BOOL】
7.array_flip($arr);// 交换键值,如有重复,后来居上,【返回新数组】
8.array_reverse($arr,[true|false]);//数组顺序反转,param2是否保留原来键值【返回新关联/索引数组】
9.array_column(array(),’name'[,name_two]) — 返回数组中指定的name列[可选参数,如果有返回name=>name_two的形式]【返回一维数组】
3.元素个数和唯一性
1.array_unique($arr);//去掉$arr中的重复值,重复的保留第一个值,【返回数组,键值保留】
2.array_count_values($arr)//统计数组值出现的次数,【返回数组,KEY为原来数组的值,VALUE为统计的次数】
3.count($arr[,1])/sizeof();//统计$arr的元素个数,参数”1″表示统计多维数组开启,默认0为关闭【返回统计个数】
4.回调函数
1.array_filter($arr,”function”);//把$arr放到函数function中处理,【返回判断为TRUE的数据组成新数组,键值保留】
2.array_walk($arr,”function”[,”data”]);//把$arr放到function(&$v,$k,$data)中处理【返回值为bool】
3.array_map(“function”,$arr,$arr2,$arr3,….);//把所有数组返回到回调函数统一处理,【返回数组】
4.array_reduce($arr,myfunction[,initial]):把一维数组$arr中的值依次传到自定义函数myfunction($v1,$v2)的v2上,v1为累加值类似于( .= ),[如果有initial,先把其当v1传进去]【返回字符串】
5.拆分,合并,分解,接合数组
1.array_slice($arr,1[,2]);//在$arr中,从第二个开始取[,返回俩个值]【返回新数组(对原数组无影响),键值保留】
2.array_splice($arr,1[,2,”aaa”,”bb”]);//删除或替换,从$arr第二个开始取,删除或替换2个值【返回值为新数组,拆掉原数组】
3.array_combine($arr1,$arr2);//数组$arr1为KEY,$arr2为VALUES结合形成新索引数组【返回索引数组】
4.array_merge($arr1,$arr2,$arr3…);//数组进行合并,保留键值,有重复,后来者居上【返回新数组】
array_merge发现有key值相同的,取后者;
$arr1+$arr2 发现有key值相同的,取前者,第二个重复的值丢弃
5.array_intersect($arr1,$arr2)//返回两个数组的交集,键值不变
6.array_diff($arr1,$arr2)//返回两数组的差集,返回的值为第一个数组的值,键值不变
7.array_chunk($arr,2)//分割数组,把$arr按照【2个为一组】均等分割【返回一个二维数组】
6.数组的数据结构【2.无返回值,传值引用,就直接对原数组进行了修改】
1.array_shift($arr)//从开头,删除数组第一个元素
2.array_unshift($arr,”one”,”two”)//从开头,添加元素
3.array_pop($arr)//从结尾,删除数组最后一个元素
4.array_push($arr,”aaa”);//从结尾,添加元素
6.current($arr)//返回数组中的当前单元 比如是关联数组是不知道下标,可以输出当前数组的办法解决
7.key($arr)//返回当前指针指向元素的键值
8.next($arr)//当前指针下移
9.pre($arr)//当前指针上移
10.end($arr)//指针指到最后
11.reset($arr)//指针回归到开头
12.unset($arr)//销毁此数组
7.其他
1.array_rand($arr,2);//随机返回两个$arr数组当中的key【返回值为值或者数组】
2.shuffle($arr)//随机的重组$arr,顺序变乱【返回新数组,保留键值】
3.array_sum($arr);//返回$arr的value的和【返回一个值】
4.range(0,10,2,)//快速创建0,10的数组,间隔为2,所以有5个值【返回新索引数组】
5.http_build_query($arr)//把关联数组转换成一个经过urlencode加密的URL eg:array[“a”=>2];=>URL:a=2&
字符串函数
返回bool
1.isset($a)//当$a=NULL 或不存在,返回false,反之为true
2.empty($a)//当$a=NULL/”/array()/0/’0’/不存在 时 返回true,反之为false
返回值为自字符
1.substr(字符串,开始地方,[返回字符串的长度]);// 截取字符串的一部分,第一个字符位置为0
2.substr_replace($str,”aaa”,start[,length]);在$str上操作,从第start个开始,把【后边】的字符[全/或length个]替换
3.sub_count($str,”is”[,5,10]);//[ 从第五个字符开始,搜索长度为10,]搜索is在$str中出现的次数,【返回次数】
4.strstr($email,”@”[,true]) //从头开始搜索,无true返回@后边字符,有true返回@前边的字符[strrchr对比]
5.strrchr($email,”@”)//从结尾开始搜索,返回@后的所有字符
6.str_replace(被替换词,替换词,被搜索字符串,[统计替换次数$num]) 前两个参数也可为数组,两个数组元素个数相同
7.str_repeat($str,num);//重复$str字符串 num次,
返回值为数字类的
1.strpos($str,”@”);//返回@【第一次出现的位置】
2.strrpos($str,”@”);//返回@【最后一次出现的位置】
3.str_word_count($str[,0/1/2]);
//返回$str中单词的数量[0指返回次数,默认值/1指以数组形式返回单词值/2指返回关联数组,k为单词首字母下标,v单词值]
4.strcmp($str1,$str2);//按ASCII码比较 str1>str2 则返回1 相等返回0 <返回-1 strcasecmp不区分大小写的比较
5.strnatcmp($str1,$str2);//按自然数的排序比较,上边的比较10<2;本函数比较10>2,按自然数大小来的
strcasecmp($str1,$str2);strnatcasecmp//以上4个函数,$str1,$str2比较,【返回值:相等0,小于-1,大于1】
6. number_format(10000[,2]); //==》10,000.00 把第一个参数格式化,保留2位小数
7. strlen($string);成功则返回字符串 $string 的长度
8. mb_strlen($string,’utf8′);//获取字符串$string长度,多字节的字符被计为 1。
文本处理类
1.strtoupper($str)//字母全转为大写【返回全大写字符串】
2.strtolower()//字母全转为小写【返回全小写字符串】
3.strtotime(‘2015-10-10 10:10:10’);//指定时间转换为时间戳【返回时间戳】
4.str_pad($str,length,[—,STR_PAD_BOTH]); //在$str的两边填补“—“,注意,length若小于$str长度,不填补
5.trim($str[,”a”,STR_PAD_BOTH])// 去除两边/左/右的空白或”a”,默认是空白,或自定义字符
6.floatval(“123.45aa”)//=》获取变量的浮点值【123.45】
7.ucfirst()//整个$str首字母大写
8.ucword()//$str每个单词首字母大写
HTML类处理
1.htmlspecialchars($str)//函数把【预定义字符】转换为【 HTML 实体】,&转换成&
htmlspecialchars_decode($str);//把【HTML实体】转换成【预定义字符】,&转换成&
2.htmlentities($str);,函数把【预定义字符】转换为【 HTML 实体】,&转换成&,有乱码问题,注意第二第三个参数,若编码不正确,会在实体化时把信息丢失
html_entity_decode($str)////把【HTML实体】转换成【预定义字符】,&转换成&, > 转成 <
3.addslashes($html); //添加转义字符“/”
stripslashes($html); //删除转义字符“/”
4.strip_tags($html); //去除HTML标签
5.nl2br($str) //在$str中的换行/n前插入<br>,因为\n在源码可以换行,但是在浏览器窗口不行,有这个就可以
6.iconv( from_charset ; to_charset,$str); //转化字符格式 $file_name = iconv(“gb2312″,”utf-8”,$file_name);
正则函数[原则,能用字符串函数解决不用正则,速度问题]
字符串的匹配查找
1.preg_match($pattern,$subject,$arr);//按正则$pattern处理$subject,第一次匹配结果返回到数组中【函数的返回值为匹配次数】
2.preg_match_all($pattern,$subject,$arr)//按正则$pattern处理$subject,全部匹配结果返回到数组中【函数的返回值为匹配次数】
3.strstr($str,”@”[,true]);
4.strpos,strrpos,substr($str,position)//联合使用
字符串的替换
1.preg_replace($pattenr,$replace,$str);//【强大的字符串处理函数】
在$str中,把$parrern匹配的值替换成$replcae【返回值为处理后的字符串】
2.str_replace($str,”aaa”,”bbb”);//把$str中的aaa换成bbb
字符串的分割和链接
1.preg_split($pattern,$str);通过一个正则表达式分隔字符串【返回值为数组】
举例:$keywords = preg_split(“/[\s,]+/”, “hypertext language, programming”);
结果Array([0] => hypertext,[1] => language[2] => programming)
2.explode(“,”,$str[,$limit_num]);//把$str按照”,”分割成一个数组[可选参数为返回数组的元素个数]【返回一个分割后的数组】
3.impolde(“+”,$arr);//把$arr里的元素按照“+”链接成一个字符串
文件处理函数
[$file=c://php/index.php]
基础函数
1.file_exists($file)//文件是否存在,【true/false】
2.filesize($file) //返回文件的大小【大小字节/出错false】
3.is_readale($file)//是否可读【返回bool】
4.is_writeable($file)//是否可写【返回bool】
5.is_executable($file)//是否可执行【返回bool】
6.filectime($file)//文件创建时间【时间戳】
7.filemtime($file)//文件修改时间【时间戳】
8.fileatime($file)//文件访问时间【时间戳】
9.stat($file)//返回文件的大部分信息【文件信息数组】
目录的基本操作
1.basename($file)//返回文件名,index.php
2.dirname($file)//返回文件的路径,c://php/
3.pathinfo($file)//返回该文件路径的所有信息
[“dirname”目录名] [“basename”文件名] [“extension”文件后缀]
目录复制,删除,统计大小使用的总结:
本质:依靠递归思想,对目录的的循环遍历,通过每一个文件的操作,得出结果
函数:
复制:copy($org,$to);mkdir()
删除:unlink($file);mrdir();
统计大小:filesize($file)
遍历目录
1.opendir($file)//打开一个目录,参数为目录名或目录路径【返回资源型的目录句柄$dir_handle,无权限返false】
2.readdir($dir_handle);//读取目录,参数为目录句柄,while,返回当前指向对象的名字,目录指针后移【返回filename,没有是返false】
3.closedir($dir_handle)//关闭打开的目录
4.rewinddir($dir_handle) //倒回目录句柄,将目录指针重置到目录开始
// 遍历文件夹$path,生成TABLE
function menu_list($root_path){
$num=0;//存储条数
$dir_handle=opendir($root_path);
echo "<table border=1 cellspacing=5 cellpadding=10 align='center'>";
echo "<caption>{$root_path}文件夹</caption>";
echo "<tr>";
echo "<td>文件名</td><td>类型</td><td>大小</td><td>创建时间</td>";
echo "</tr>";
while($file_name=readdir($dir_handle)){
if($file_name =="." || $file_name=="..")continue;
$cur_path=$root_path."/".$file_name;
$bgcolor=$num++%2==0?"#FFFFFF":"#CCCCCC";
$cate=filetype($cur_path)=="dir"?"目录":"文件";
echo "<tr color={$bgcolor}>";
$file_name = iconv_change($file_name);
echo "<td>{$file_name}</td>";
echo "<td>{$cate}</td>";
echo "<td>".filesize($cur_path)."</td>";
echo "<td>".date("Y-m-d H:i:s",filectime($cur_path))."</td>";
echo "</tr>";
}
echo "<tr><td colspan=4 align=center>文件总数为:{$num}个</td></tr>";
echo "</table>";
} 建立和删除目录
1.mkdir(“dir_name”);//建立一个空的目录
2.rmdir(“dir_name”);//删除一个空的目录
unlink(“file_name”)//删除一个文件,当删除目录是,必须删除该目录下的文件
/**
* 删除文件夹[也可以删除文件]
* @param $root_path 该文件夹的路径
*/
function del_dir($root_path){
// echo file_exists($root_path)."--<br>";
if(!file_exists($root_path))exit('文件不存在');
if(is_file($root_path))unlink($root_path);exit; $dir_handle=opendir($root_path);//打开此文件夹
while($cur_name=readdir($dir_handle)){//遍历文件夹
if($cur_name =="." || $cur_name=="..")continue;//删除前两个默认的
$cur_path=$root_path."/".$cur_name;
if(is_file($cur_path)){
//是文件,执行删除文件
del_file($cur_path);
}else{
//是文件夹,删除文件夹,递归
del_dir($cur_path);
}
}
closedir($dir_handle);
rmdir($root_path);
}
/*删除文件操作*/
function del_file($file_path){
return unlink($file_path);
} 统计目录大小【得自定义函数,不自带】
/** * 统计文件夹大小[也可以统计文件] * @param 文件夹的目录路径 * @return 返回该目录的大小 */
function dirSize($dir){
$dir_size=0;
if(!file_exists($dir))exit("文件不存在");
if(is_file($dir))return filesize($dir);//如果是文件,返回文件大小
$handle=opendir($dir);
while($cur_name=readdir($handle)){
if($cur_name=="." || $cur_name=="..")continue;
$cur_path=$dir."/".$cur_name;//获取当前文件的路径
if(is_file($dir)){
//如果是文件,累加文件大小到file_size
$dir_size+=filesize($cur_path);
}
if(is_dir($dir)){
//如果是文件夹,累加文件夹大小到file_size
$dir_size +=dirSize($cur_path);
}
}
return $dir_size;
}
/**
* 转换单位大小
* @param,data 以B为单位的字节大小
* @param,unit 转换后的单位
* @return 转换后的数字及单位,字符串格式
*/
function transform_unit($data,$unit="MB"){
$unit=strtoupper($unit);
switch ($unit) {
case 'B':
$data=$data/pow(1024, 0);
break;
case 'KB':
$data=$data/pow(1024, 1);
break;
case 'MB':
$data=$data/pow(1024, 2);
break;
case 'GB':
$data=$data/pow(1024, 3);
break;
case 'TB':
$data=$data/pow(1024, 4);
}
return round($data,2).$unit;
}
// echo transform_unit(dirSize($path),"KB"); 复制一个目录及文件【得自定义函数,不自带】
/**
* 复制文件夹,生成另一个文件夹
* @param $fromDir ,被复制的源文件夹
* @param $toDir,生成的文件夹名字
*/
function copyDir($fromDir,$toDir){
if(is_file($toDir))exit("目标地址不是文件夹");//不是文件夹返回提示
if(!file_exists($toDir))mkdir($toDir);//没有创建目标文件夹,创建
$handle=opendir($fromDir);//打开文件夹
while($cur_name=readdir($handle)){
$cur_path=$fromDir."/".$cur_name;//进入一层文件夹后,当前文件的路径
$cur_to_path=$toDir."/".$cur_name;//要复制的形成的路径
if($cur_name=="." || $cur_name=="..")continue;
if(is_file($cur_path)){
//若是文件复制当前文件到目的文件夹
copy($cur_path,$cur_to_path);
}
if(is_dir($cur_path)){
//若是文件夹,复制该文件夹
copyDir($cur_path,$cur_to_path);
}
}
closedir($handle);//关闭文件夹
}
// copyDir($path,"test");文件的基本操作
1.fopen($fileName,”模式字符r,w,x”)//打开一个文件,【返回值为资源型$handle】
2.fclose($handle) //关闭打开的文件【返回BOOL】
3.fwrite($handle,”$data”)//把$data写入$handle文件,先清空后写入,【成功返回$handle,失败返回false】
4.file_put_contents($filename,$data);//它是上边三个合起来的效果
5.file_get_contents($filename)//读取文件里的信息【返回字符串】
6.flock($handle,$operation) //用$operation锁定文件$handle
1.copy($file1,$file2);//赋值$file1,形成$file2【返回BOOL】
2.unlink($file);//删除$file文件【返回BOOL】
3.rename($file1,$file_new_name);//重命名【返回BOOL】
文件的上传
1.is_upload_file($_FILES[‘file’][‘tmp_name’]) //检查是否合法
2.move_upload_file($_FILES[‘file’][‘tmp_name’],$url); //上传合法文件到$url
注意:html:form: method=”post” ;enctype=”multipart/form-data”
文件下载
header(‘content-disposition:attachment;filename=’.basename($filename));//表示附件方式下载
header(‘content-length:’.filesize($filename));
readfile($filename);
SQL函数
1.mysql_connect(‘localhost’,”root”,”root”);//连接诶数据库
2.mysql_select_db(‘data’,$conn);//选择数据库名
3.mysql_query(‘set names utf8’);//设置编码
4.mysql_affect_array();//试返回值为关联/索引数组
5.mysql_affect_row();//返回索引数组
6.mysql_affect_assoc();//返回关联数组
7.mysql_num_rows();//返回上一次select的查询语句条数
8.mysql_affected_rows();//返回上一次insert,update,delete的数据条数
9.mysql_close();//关闭数据库
数学函数
1.ceil()//向上取整
2.floor()//向下取整
3.round();//四舍五入
4.abs();//取绝对值
5.rand(10,100)//随机取值
6.mt_rand(10,100)//随机取值,算法不同,速度更快
7.fmod()//返回除法浮点形余数
8.max(int/$arr)//取最大值
9.min(int/$arr)//取最小值
10.pow(1024,2)//返回1021的2次幂
时间函数
1.date_default_timezone_set()(‘PRC’);//设置时区为中国
date.timezone =”PRC”;//PHP.INI
2.time();//默认获取当前时间,【返回时间戳格式】
3.micritime();//获取当前时间【返回毫秒的时间戳】
4.mktime(H,i,s,m,d,Y)//指定时间转为时间戳,参数为空的时候作用与time()相同【返回时间戳格式】
5.strtotime(‘2015-10-10 10:10:10’);//指定时间转换为时间戳【返回时间戳】
6.date(“Y-m-d H:i:s”,time());//转换时间戳为日期格式【返回目标格式的字符串】
7.getdate()//获取当前时间,【返回一个数组,参数年,月,日等都有】
URL处理函数
1.urlencode($url)//对该URL进行编码;原因:防止乱码,解决空格的呢个字符不能传递问题,form也是此编码格式传递
2.urldecode($url)//对该URL进行解码
3.parse_url($url)//返回该URL的所有信息,[scheme协议][host域名] [path路径][query参数] 【返回含信息的数组】
pathinfo($url)//[“dirname”目录名] [“basename”文件名] [“extension”文件后缀]【返回含信息的数组,下标不同】
4.get_meta_tags($url)//获取该页面的所有META标签【返回关联数组】
JSON
1.json_encode($data);//对变量进行JSON编码
2.json_decode($data)//对JSON格式的字符串进行解码
3.json_last_error();//返回最后一次反生的错误
其他函数
sleep(10)//脚本执行到这里后,延迟10秒继续执行
serialize()//返回字符串,此字符串包含了表示
value 的字节流,可以存储于任何地方。unserialize()//对单一的已序列化的变量进行操作,将其转换回 PHP 的值。
当序列化对象时,PHP 将试图在序列动作之前调用该对象的成员函数 __sleep()。这样就允许对象在被序列化之前做任何清除操作。类似的,当使用 unserialize() 恢复对象时, 将调用 __wakeup() 成员函数。
原文出处:https://blog.csdn.net/u010227042/article/details/79049793