正所谓,民生无小事,今日多关注,今天我们利用多线程来爬取阳光问政,关注一下老百姓需要解决什么问题。
线程
什么是线程
线程是轻量级进程,是操作系统能够进行运算调度的最小单位,它被包涵在进程之中,是进程中的实际运作单位。
其生命周期可以分为五个状态——新建、就绪、运行、阻塞、终止,如下图所示:
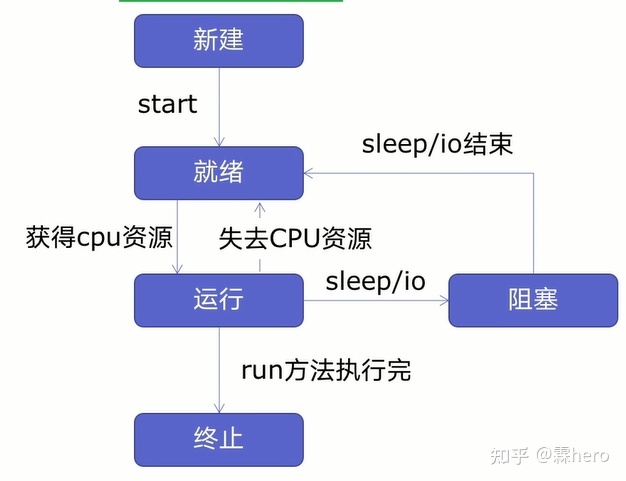
- 新建状态:新创建的线程在调用 start() 方法之前,不会得到执行;
- 就绪状态:新建状态的线程调用 start() 方法后,该线程就转换到就绪状态,当获取到CPU资源就可以执行;
- 运行状态:就绪状态的线程得到了 CPU资源,并开始执行 target 参数执行的目标函数或者 run() 方法;
- 阻塞状态:当 CPU 对多个线程进行调度时,对于获得 CPU 调度却没有执行完毕的线程,该线程就进入阻塞状态;
- 终止状态:线程执行结束、发生异常(Exception)或错误(Error),线程就会进入终止状态。
线程创建
创建线程可以分为五步:编写执行程序、创建线程类、在线程类run方法中调用要执行的程序、开启线程和等待线程结束。
编写执行程序
import time
def print_time(threadName):
for i in range(5):
time.sleep(0.5)
timestamp = time.time()
date = time.localtime(timestamp)
Now_date = time.strftime('%Y-%m-%d %H:%M:%S', date)
print ("%s: %s" % (threadName, Now_date))在执行程序中,我们通过time来获取当前系统时间,由于程序执行速度是很快的,所以我们通过time.sleep()方法让程序休眠0.5秒,这样我们就可以看到线程的交替执行。
创建线程类
import threading
class myThread (threading.Thread):
def __init__(self, name):
super(myThread,self).__init__()
self.name = name
def run(self):
pass首先导入线程模块threading,创建myThread()线程类并通过threading.Thread来继承线程属性,调用super()方法并初始化name变量。
run()方法
def run(self):
print ("开始线程:" + self.name)
print_time(self.name)
print ("退出线程:" + self.name)在run方法中,我们通过调用print_time()方法并传入self.name参数来执行第一步编写的执行程序。
开启、等待线程
线程类和执行程序都写好了,接下来开启线程并等待线程结束,具体代码如下所示:
thread1 = myThread("Thread-1")
thread2 = myThread("Thread-2")
thread1.start()
thread2.start()
thread1.join()
thread2.join()
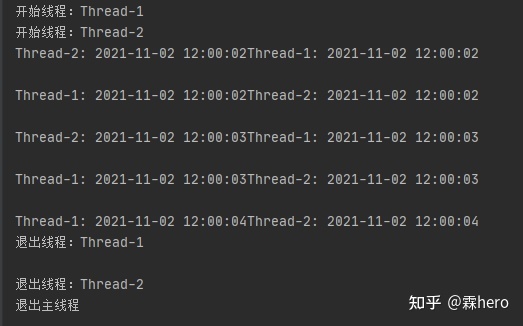
print ("退出主线程")这里我们创建了两个线程,首先通过实例化线程类myThread()并传入线程名,调用start()方法使线程处于就绪状态,再调用join()方法等待线程结束。
运行结果如下所示:
爬前分析
首先进入阳光问政最新问政网页并打开开发者模式,如下图所示:
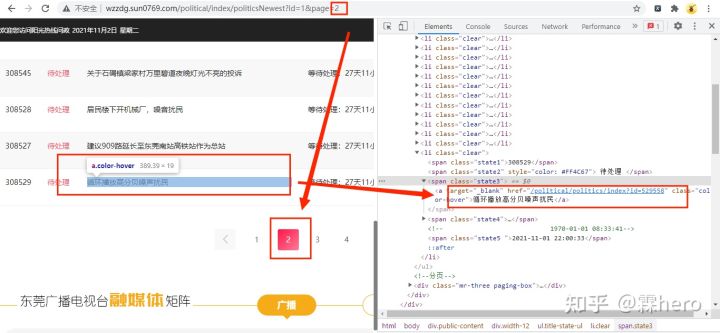
这个网站比较简单,网页的URL链接最后一个数字就是它的页码,所以我们构造url链接时,可以这样:
for i in range(1,6):
url=f'http://wzzdg.sun0769.com/political/index/politicsNewest?id=1&page={i}'这样就可以获取多页数据了,在源代码中也有我们想要的详情网页url链接,其存放在上图的右边红框中。
随机打开一个问政问题并打开开发者模式,如下图所示:
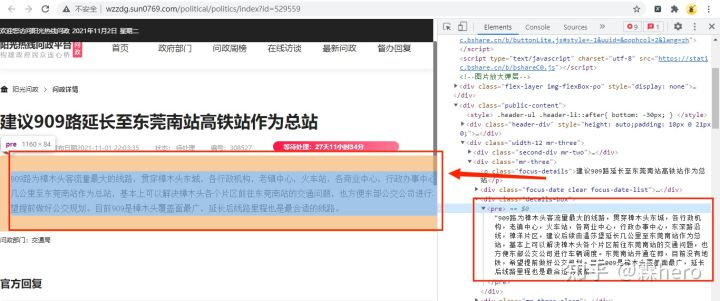
可以发现该url为http://wzzdg.sun0769.com/political/politics/index?id=529559,对比上上图的详情网页url,只需要在获取到的url链接前面添加http://wzzdg.sun0769即可。
详情网页也很简单,我们想要的数据在源代码中也有,所以我们待会只要获取URL链接页面的源代码即可获取到所有数据。
实战演练
在实战演练中,我们首先通过编写单线程爬虫来爬取阳光问政的数据,再通过多线程程序执行单线程爬虫。
单线程爬虫
获取详情网页url
首先获取详情网页的url链接,主要代码如下所示:
import requests
import parsel
import pymysql
def get_link():
for i in range(1,6):
url=f'http://wzzdg.sun0769.com/political/index/politicsNewest?id=1&page={i}'
response=requests.get(url,headers=headers)
Xapth=parsel.Selector(response.text)
f = open('url.txt', 'a', encoding='utf-8')
ul_list = Xapth.xpath('//html/body/div[2]/div[3]/ul[2]/li')
for li in ul_list:
url_href='https://wzzdg.sun0769.com/'+li.xpath('./span[3]/a/@href').extract_first()
f.write(url_href)
f.write('\n')
get_data(url_href)我们一共获取5页数据,每页数据有15条详情网页的URL链接,通过requests.get()方法发出网络请求,并通过parsel.Selector()方法来解析响应的文本数据,最后将获取到的url链接传入到自定义get_data()方法。
注意:这里我们把url链接保存在一个txt文本中,方便我们在多线程里使用所有详情网页的url链接。
获取详情网页数据
获取详情网页的url后,接下来就获取其内容了,具体代码如下所示:
def get_data(i):
response=requests.get(i,headers=headers)
Xapth=parsel.Selector(response.text)
data={}
data['number_id']=Xapth.xpath('/html/body/div[3]/div[2]/div[2]/div[1]/span[4]/text()').extract_first().replace('编号:','')
data['state_now']=Xapth.xpath('/html/body/div[3]/div[2]/div[2]/div[1]/span[3]/text()').extract_first().replace('状态:','').strip()
data['PoliticalTitle']=Xapth.xpath('/html/body/div[3]/div[2]/div[2]/p/text()').extract_first()
data['PoliticalTime']=Xapth.xpath('/html/body/div[3]/div[2]/div[2]/div[1]/span[2]/text()').extract_first().replace('发布日期','')
data['url_href']=i
data['text']=Xapth.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').extract_first().replace('\n','').replace('\r','')
saving_scenery_data(list(data.values()))获取详情网页的数据和获取url链接代码差不多,这里我就不一一解释了,最后我们把数据传递到自定义方法saving_sunshine_data()中。
保存数据
这次数据我们保存在MySQL数据库中,主要代码如下图所示:
def saving_scenery_data(srr):
db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='Politics')
cursor = db.cursor()
sql = 'insert into problem_data(number_id, state_now, PoliticalTitle, PoliticalTime, url_href,text) values(%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,srr)
db.commit()
except:
db.rollback()
db.close()首先连接数据库,通过cursor()方法获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接。当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
启动程序
好了,主要代码已经写好了,接下来编写启动程序的代码,主要代码如下图所示:
if __name__ == '__main__':
t1=time.time()
get_link()
t2=time.time()
print(t2-t1)这里我们通过time.time()方法来获取爬虫程序的执行时间。
运行结果如下图所示:
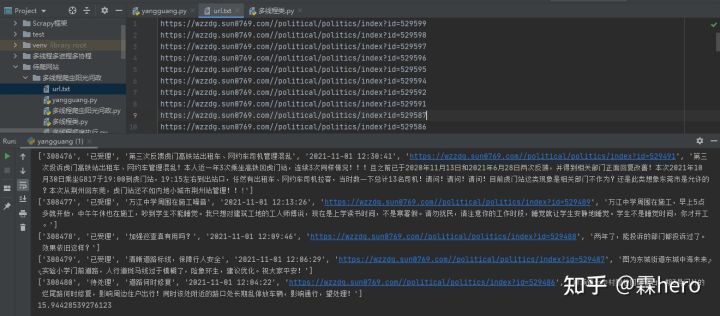
从结果来看,单线程爬取数据用了16秒,接下来编写多线程来爬取数据。
多线程爬虫
刚才单线程爬虫的文件名为yangguang.py,可以直接调用单线程爬虫方法来编写多线程爬虫,首先创建多线程爬虫类,主要代码如下所示:
import yangguang
import threading
import time
f=open('url.txt',mode='r')
class mythread(threading.Thread):
def __init__(self,f):
super(mythread,self).__init__()
self.f=f
def run(self)->None:
for i in self.f:
yangguang.get_data(i)首先导入单线程爬虫yangguang.py文件,打开刚才单线程爬虫保存的txt文件,再创建mythread()类并初始化线程类,重写run()方法,通过for循环把txt文件中的url读取并传递在单线程爬虫yangguang.get_data()方法中。
好了,多线程类写好了,接下来编写执行代码,主要代码如下所示:
if __name__ == '__main__':
t1=time.time()
yangguang.create_db()
threads = [mythread(f) for i in range(10)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
t2=time.time()
print(t2-t1)这里我们创建了10个线程,运行结果如下所示:
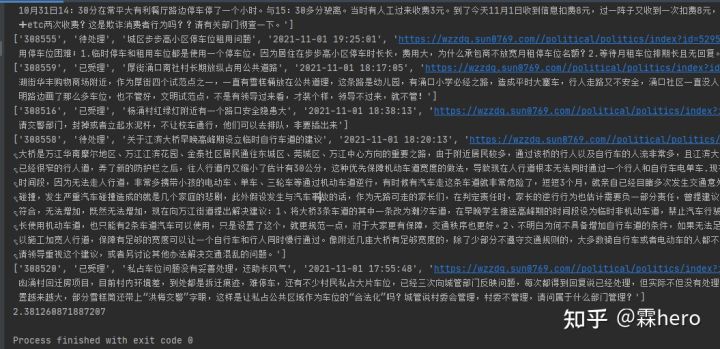
开启十个线程来爬取数据,一共用了2.4秒,大大提高了爬虫效率。
好了,多线程爬取阳光问政就讲到这里了,感谢观看!!!
– END –