前面写过的phantomJs,研究几天后发现phantomJs虽然在业内有一定的影响力,但后继乏力,主要还是缺乏维护人员,导致项目依赖的chrome内核版本太低,无人解决的BUG太多(1000+),现在这个环境已经越来越满足不了真实的前端模拟以及各种新的特性需求(比如高版本Chrome的执行环境特性,比如JS执行和渲染等都相差很大),GitHub参照:点击这里。
谷歌浏览器在17年自行开发了Chrome Headless特性,并与之同时推出了puppeteer,可以理解成我们日常使用的Chrome的无界面版本以及对其进行操控的js接口套装,官方介绍参照:点击这里。
借助puppeteer,我们实际上是通过调用Chrome DevTools开放的接口与Chrome通信,Chrome DevTools的接口很复杂,但puppeteer对其进行了封装,我们调用起来还是很方便的。写几个简单例子:
Demo1:打开百度,并保存截图
下面代码保存在 baidu.js中(当然需要提前初始化package.json等操作,默认大家都了解的):
const puppeteer = require(‘puppeteer’);
(async () => {
const browser = await puppeteer.launch({
headless: true
})
const page = await browser.newPage()
await page.goto(‘http://www.baidu.com’)
await page.screenshot({
path: ‘c:/temp/baidu.png’
})
})()
通过 node baidu.js 就可以将截图保存下来,下面是效果图:

当然上面的只是最简单的操作,涉及到的API也少,查看完整API可以:点击这里
再来丰富下上面的操作:
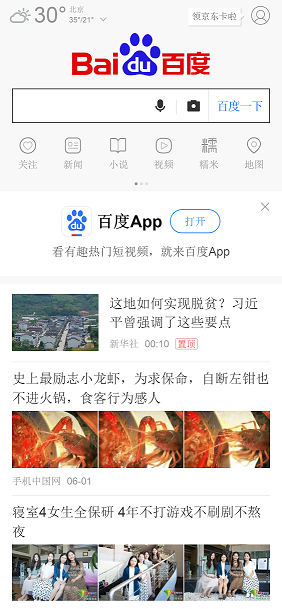
Demo2:iPhoneX模式打开百度,并保存截图
代码如下,相比demo1其实只是多了几行代码,也就是调用了 page.emulate方法按照给定设备对页面的尺寸进行了设定:
const devices = require(‘puppeteer/DeviceDescriptors’)
const puppeteer = require(‘puppeteer’);
(async () => {
const browser = await puppeteer.launch({
headless: true
})
const page = await browser.newPage()
await page.emulate(devices[‘iPhone X’])
await page.goto(‘http://www.baidu.com’)
await page.screenshot({
path: ‘c:/temp/baidu_iphone_X.png’
})
})()
截图如下:
针对device设备的完整列表,可以参照源码:点击这里,(PS:大家都要学会找源码,读源码,项目中经常碰到引用插件的问题,通过查找源码可以加深对问题的理解,才可能真正解决)
上面两个例子都是比较简单的操作,只有加载页面和截图,没有用户交互操作,我们继续
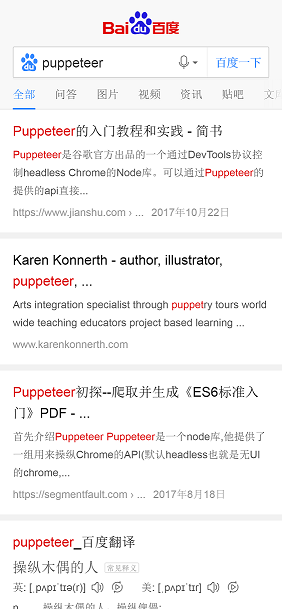
Demo3:iPhoneX模式打开百度,搜索puppeteer关键字,跳转到查询结果页面后,保存截图
这个demo真正增加的步骤也就三个:
找到 输入文本框 并填充关键字 puppeteer;
找到 百度一下 按钮并点击;
等待页面跳转显示查询结果;
代码如下:
const devices = require(‘puppeteer/DeviceDescriptors’)
const puppeteer = require(‘puppeteer’);
(async () => {
const browser = await puppeteer.launch({
headless: true
})
const page = await browser.newPage()
await page.emulate(devices[‘iPhone X’])
await page.goto(‘http://www.baidu.com’)
await page.type(‘#index-kw’, ‘puppeteer’)
await page.click(‘#index-bn’)
await page.waitForNavigation({ timeout: 3000 })
await page.screenshot({
path: ‘c:/temp/baidu_iphone_X_search_puppeteer.png’
})
})()
上面的加粗的三行代码就对应多出的三个步骤,需要留意的是,在PC直接访问百度和模拟iPhoneX访问百度拿到的文本框和按钮的id是不同的,也就是说,百度并不是直接拿一个站点做mediaQuery之类设置供PC和移动端共享,而是两个完全不同的页面,这里不讨论优缺点,如果大家想要在PC看iPhoneX访问的效果就要利用ChromeDevTools改下设置:
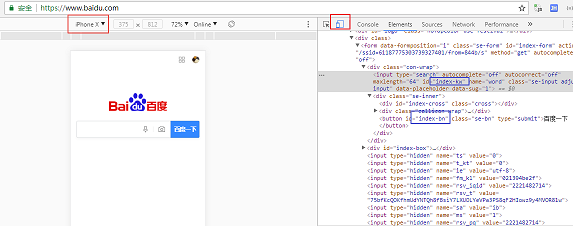
两个红色方框是设置的地方,蓝色方框标注两个元素的id
最终截图见下:
好了,puppeteer的入门及实践(1)就到此为止了,总结下,puppeteer作为谷歌出品的前端利器,想象空间是很大的,在爬虫、测试自动化等方面都可以很好胜任,跟其他测试工具不同,不再是模拟谷歌执行引擎再去渲染,而是一个真正在运行的浏览器,只是移除了真实的界面渲染。作为一个入门课程,很多细节都没详述,比如可以通过传参 headless: false 让puppeteer操作Chrome的过程可视化,各步骤可以指定间隔时间,还有插件可以录制等,这些更精彩的留待后面再写。
文中所有DEMO源码参照:
https://github.com/wu0792/puppeteer_01
作者:子非鱼_fish
链接:https://www.jianshu.com/p/56babda610f9
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。