前言:本文主要讲w3lib库的四个函数
html.remove_tags()
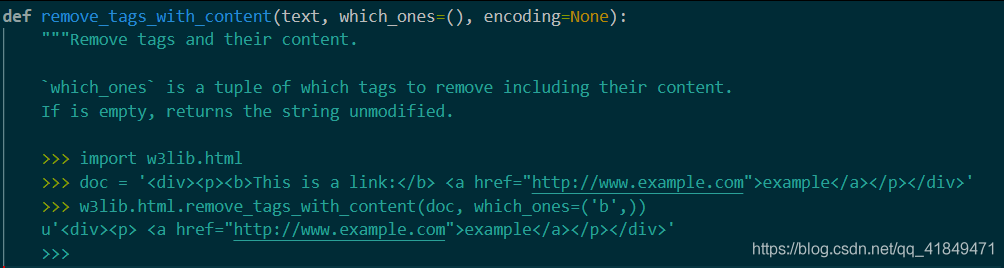
html.remove_tags_with_content()
html.remove_comments()
html.remove_entities()remove_tags
作用:去除或保留标签,但是仅仅是去除标签,正文部分是不做处理的
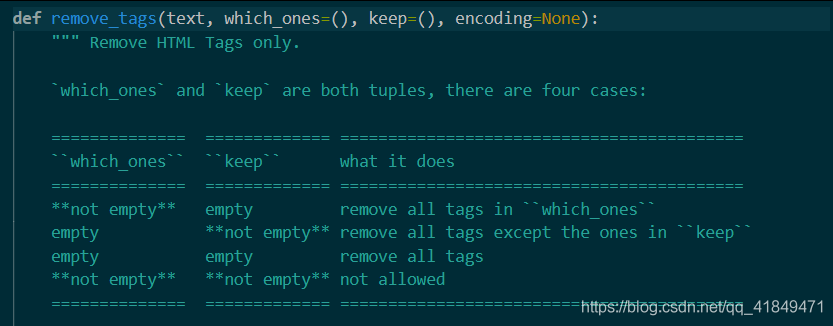
看其函数具有四个变量,
第一个是文本,即你需要传入的网页源码,必须是字符串
第二个是你要去除掉的标签,需要传入的参数类型是元组,原理是根据正则匹配去除的
第三个是你要保留的标签,需要传入的参数类型依旧是元组
第四个是编码
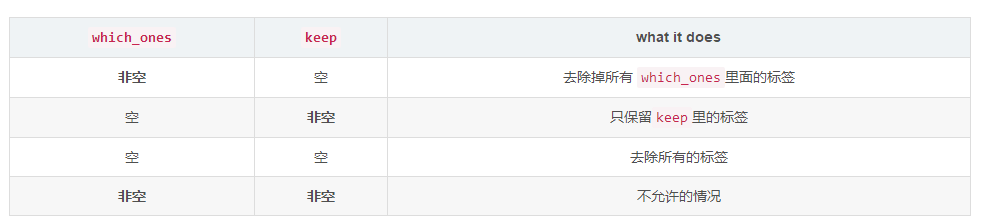
看备注我们可以得知,第二第三个参数总共有四种状态
代码示例:
以下的代码以example.com的部分源码进行测试
</pre> <div> <h1>Example Domain</h1> This domain is established to be used for illustrative examples in documents. You may use this domain in examples without prior coordination or asking for permission. <a href="http://www.iana.org/domains/example">More information...</a></div> <pre>from w3lib import html import requests from lxml import etree res = requests.get("http://www.example.com/") response = etree.HTML(res.content) temp = response.xpath('//body') # 返回值为一个列表 doc = etree.tostring(temp[0]) # 将定位到的元素转成str,即获得源码 # 以上代码只是为了获取body的源码,与函数演示无关 result = html.remove_tags(doc) # 标签全部去除 print(result)只留下正文部分
result = html.remove_tags(doc,which_ones = ('body','h1','div'))p标签与a标签还留着
remove_tags_with_content
作用:去除标签,包括其正文部分
参数变成了三个,与上面的用法一致,只是少了一个keep参数,无法保留,只能去除
remove_comments
作用:去除掉网页的注释
参数只有两个,一个是text(网页源码),str类型,一个是编码(encoding)
from w3lib.html import remove_comments remove_comments(b"test <!--textcoment--> whatever")结果即test whatever
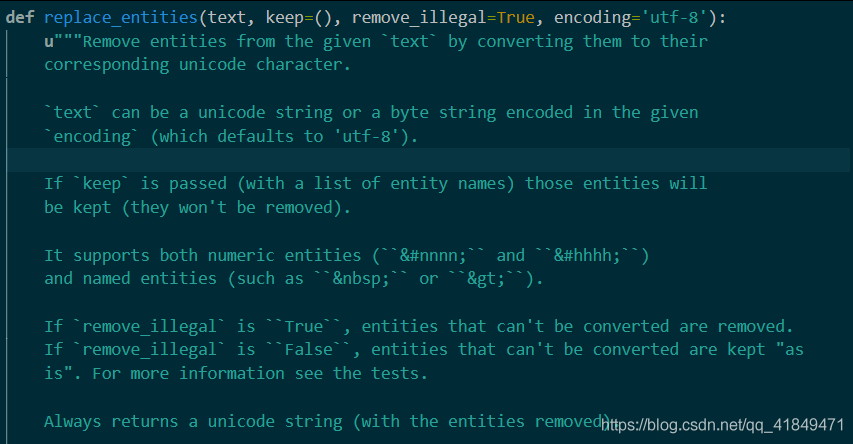
remove_entities
作用:将网页中的一些特殊字符的源码显示改变成正常显示(个人理解)
官方解释是通过将实体转换为相应的unicode字符,从给定的text中删除实体。
在函数源码中已声明,该函数即将被剔除,将被replace_entities取代
函数具有三个参数,第一个是源码(字符串),第二个是你需要保留不变的实体(元组),
第三个是是否删除无法转换的实体(true删除,false不删除),
第四个是编码,默认utf-8from w3lib.html import replace_entities print(replace_entities(b'Price: £100'))以下为结果
Price: £100该模块还是挺有意思的,还有几个常用的函数等我有空了会再次补充的~
对您有帮助的话记得点个赞哦~
https://blog.csdn.net/qq_41849471/article/details/89527706